Merkle Trees are valued in the blockchain space for their ability to commit to huge amounts of data with a concise value. As a result, they form the cornerstone of many protocols, making the performance of their implementations absolutely crucial for protocol responsiveness.
One such protocol is the Miden blockchain, with whom Reilabs has recently been working to implement a fast, persistent Sparse Merkle Tree (SMT) data structure in order to remove a significant bottleneck to the protocol’s ability to scale. LargeSMT, as this implementation is called, has significantly reduced memory usage while providing sufficient performance to achieve Miden’s goal of 10K transactions per second (TPS).
Read on to see how we did it!
Miden and Merkle Trees
Miden is a blockchain designed to break away from the limitations of the centralized design of traditional chains. It is built to enable privacy-perserving and high-throughput applications at block rates far higher than that of mainnet, and LargeSMT is a necessary piece of the puzzle to achieve the network’s 10K TPS goal.
The Miden protocol makes heavy use of Merkle Trees to store the state of every block, but prior to the introduction of LargeSMT the trees it used were purely in memory. This meant that while they could easily hit 10K TPS, scaling up to the numbers of leaves— \(2^{40}\) 256-bit elemens—that the network needs resulted in prohibitively long startup and vast memory requirements. LargeSMT achieves 10K TPS while reducing memory usage to far more manageable levels.
Two particularly problematic use-cases for these Merkle Trees are the account tree and the nullifier tree, both of which experience extremely heavy traffic. The Account Tree represents the current state of all accounts in the network, while the Nullifier Tree tracks the consumed notes—asynchronous messages between accounts—to ensure they are not replayed. These are the initial targets for LargeSMT.
A Merkle Tree is a binary tree that has two main properties.
Each leaf node contains the hash value of some data.
Every non-leaf node contains the hash value of the concatenation of its two children.
The structure of this tree means that if a change is made to any leaf, the root of the tree will change, and hence the root uniquely identifies the entire tree.
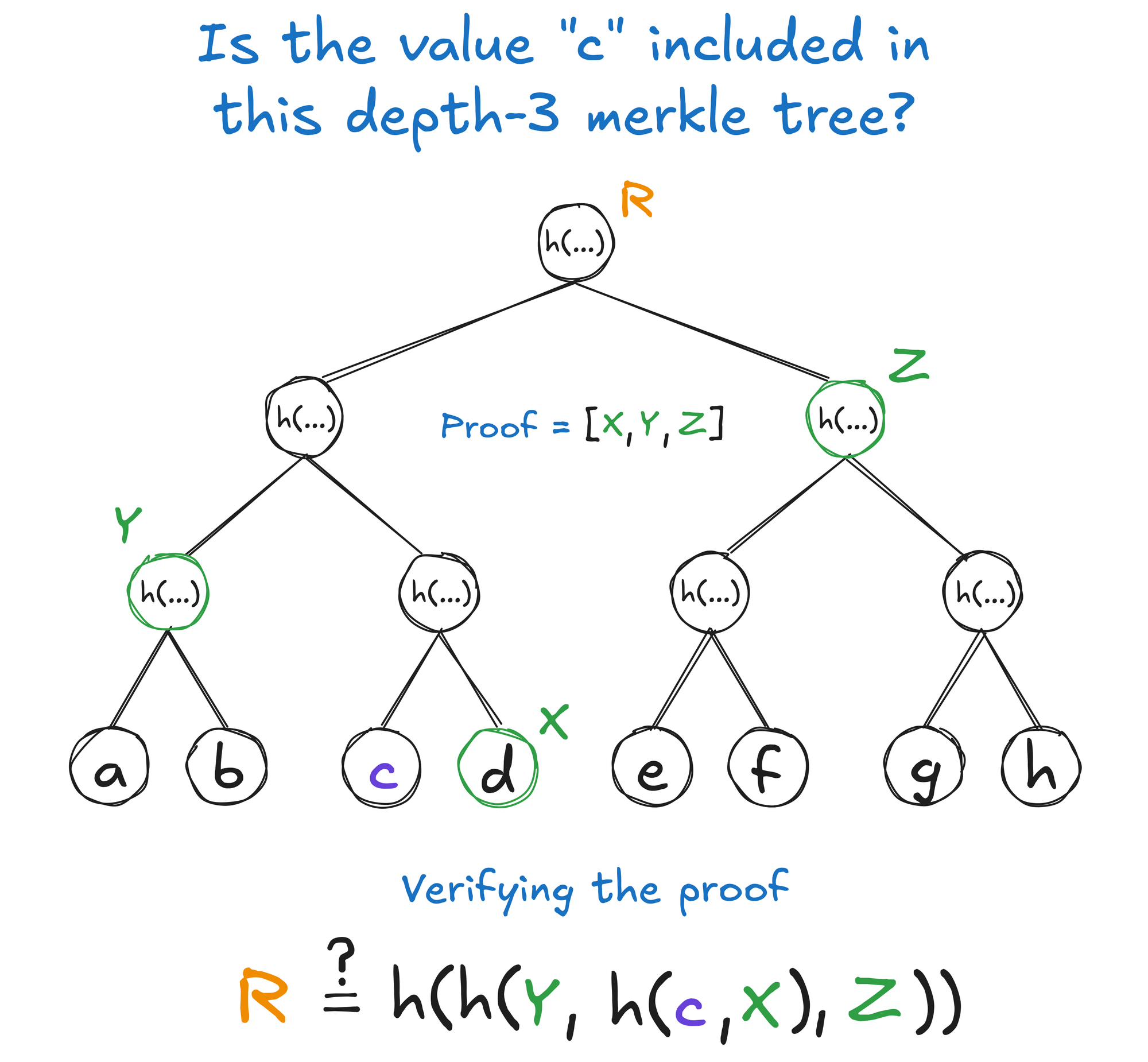
Depth-three merkle tree with the leaf node c highlighted, the merkle proof being equal to the chain of nodes [X, Y, Z] and the process of verifying the proof being checking that R ?= h(h(Y, h(c, X), Z)).
To verify the inclusion of a value in the tree you only need to have the value and a list of auxiliary elements to aid you in computing the intermediate hashes. Known as a Merkle Proof, this provides all the information you need to check that the value is included in the tree with a given root, without needing access to the contents of every leaf in the tree.
Merkle Trees in Miden
While the commitments that Merkle Trees can provide are compact, the full tree is necessarily not so compact. A record of the value for every node in the tree has to be located somewhere, and the necessary storage for this could eventually balloon to an impossible size. To that end, Miden’s in memory tree implementation already employed two main optimizations.
The first is that it is sparse, meaning that it only stores the data for the intermediary nodes and the leaves that actually contain a real value. This makes the size of the tree’s data orders of magnitude smaller, while still supporting the target residency.
The second is limiting the tree to depth 64, and collapsing everything below that into single leaves. By borrowing from the linear probing technique used in hash table data structures, and recognizing that it is very unlikely for a large number of values to share even their prefix, this technique—called Leaf Compaction—allows a depth-64 tree to still uniquely store 256-bit values as follows:
We have a merkle tree with a depth of only 64, rather than 256.
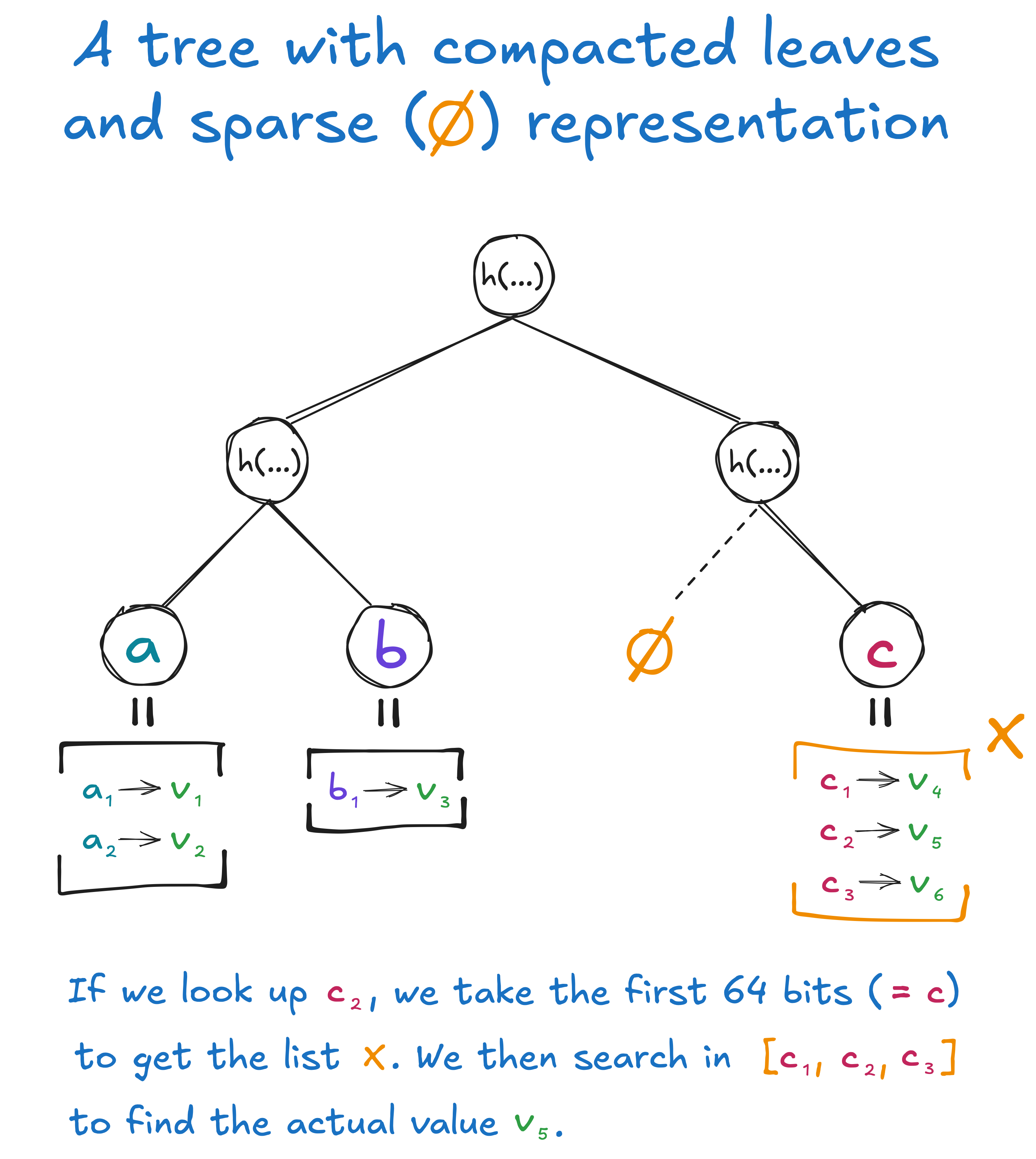
Each leaf node is now treated as a “bucket” that may contain multiple values in a sequence, where each is a full 256-bit value. This sequence is kept sorted for search efficiency. In practice, Miden stores key-value pairs in the sequence, each of which contains 256 bits.
When querying the tree, the leaf is identified by taking the 64-bit prefix of the full value, which is sufficient to uniquely identify a leaf in this depth-64 tree.
The full value is then looked up in the selected sequence, which probabilistically only has a small number of elements at Miden’s target residency.
The eagle-eyed reader will note that this means that the form of the Merkle Proof for such a tree is different to the one discussed above. The proof now contains not only the auxiliary values, but also the other values from the same bucket as the element.
A depth-2 merkle tree. The first leaf is for leaf value a while its compacted values are the mappings a1 -> v1 and a2 -> v2. The second leaf is for leaf value b with a single compacted value being the mapping b1 -> v3. The third leaf does not exist due to the sparse representation. The fourth leaf is for leaf value c with its compacted values being the mappings c1 -> v4, c2 -> v5 , and c3 -> v6.
To understand why this is so valuable, consider two sparse trees, \(t_1\) of depth 64 and \(t_2\) of depth 256, both of which contain the same elements. The path to a value in \(t_1\) (resolving to a bucket containing \(n\) elements) contains \(192 - n\) fewer elements than the path to the same value in \(t_2\).
Probability thus says that the size of \(t_1\) on disk is significantly smaller than \(t_2\) . Not only that, but verifying a Merkle Proof in \(t_1\) requires computing \(64 + n\) hashes. In \(t_2\) , it requires computing 256 hashes. The proofs for \(t_1\) are also—on average—smaller, which reduces communication overhead.
Handling Trees that are Too Big for RAM
The existing performance of this SMT structure—and its ability to achieve the 10K TPS goal—are outweighed in practice by its in-memory implementation. This both required significant amounts of memory at the upper end of the projected residency, and also forced each network node to take the (oft excessive) time to rebuild the tree from scratch at startup.
A naïve approach might simply persist the data from the in-memory tree to disk by storing them under some key (be it a hash or an index) in a key-value store on disk. In addition to being difficult to parallelize, this approach yields two significant inefficiencies:
The read patterns on disk are unlikely to be usefully sequential, resulting in unpredictable and latency-heavy I/O in practical usage.
It causes the disk to do far more work than is necessary as each read means the disk has to read one or more 4 KiB blocks while only 256-bits are needed.
The solution has to ensure bounded memory usage with a predictable and dense storage layout on disk, while also being designed so that throughput scales with core count and so that node boot time is minimized.
How Did We Improve the Situation?
Enter LargeSMT, a hybrid system that enables efficient queries alongside resilient on-disk persistence of sparse merkle trees with leaf compaction. It retains the capabilities of the existing data structure without the risk of corruption or data loss. The key elements of LargeSMT are as follows:
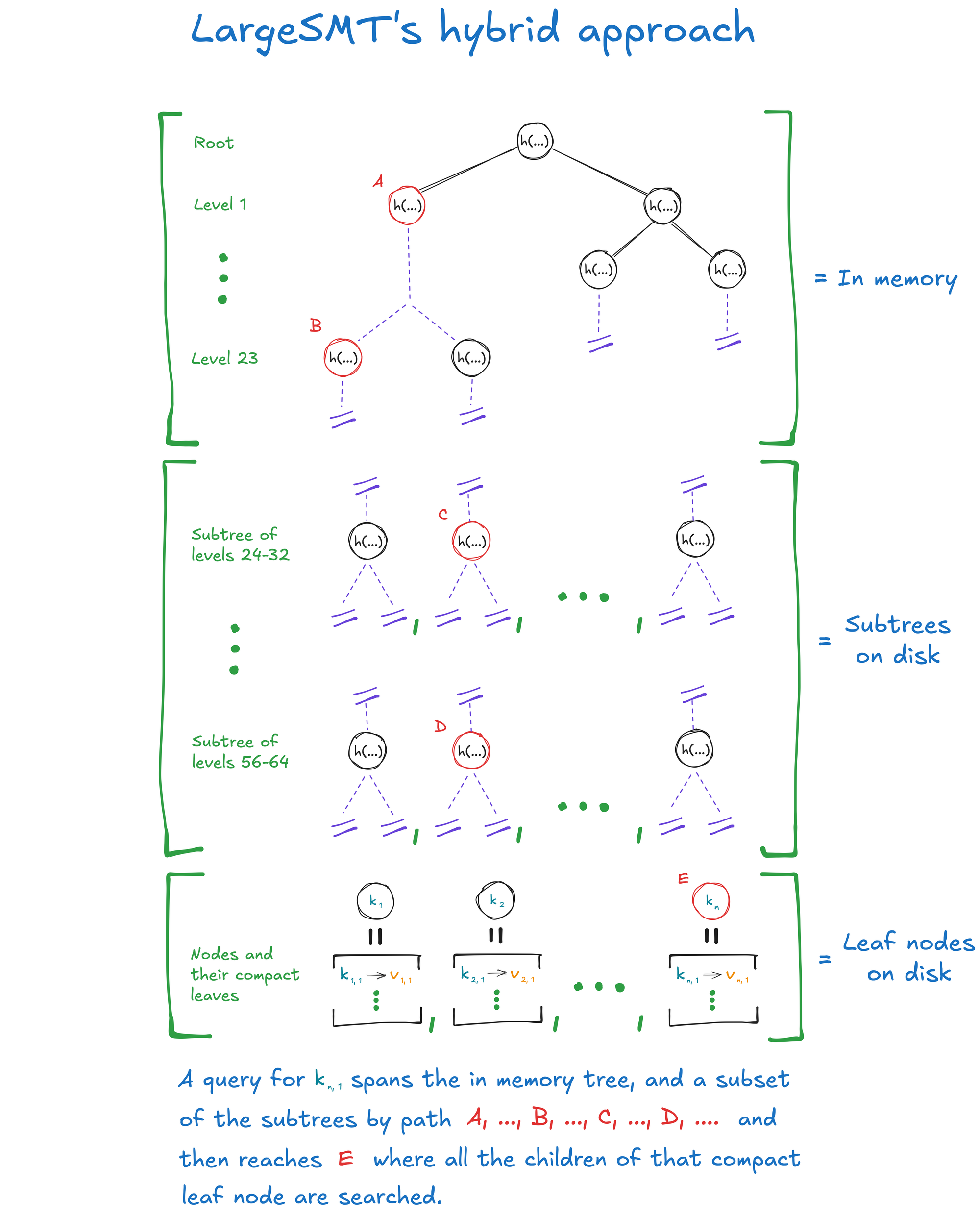
In-RAM Tree Levels: The most frequently-queried levels of the SMT are kept in memory, removing the need to wait for I/O when querying the common traversal prefix. These levels are kept fully materialized—even though the on-disk tree is sparse—as they are very unlikely to take much advantage of sparsity. This step increases memory consumption to decrease the time taken for queries against this common prefix. In the current deployment this trade of 1GiB of extra RAM usage for a 38% reduction in I/O load has been crucial to achieving the goal of 10K TPS.
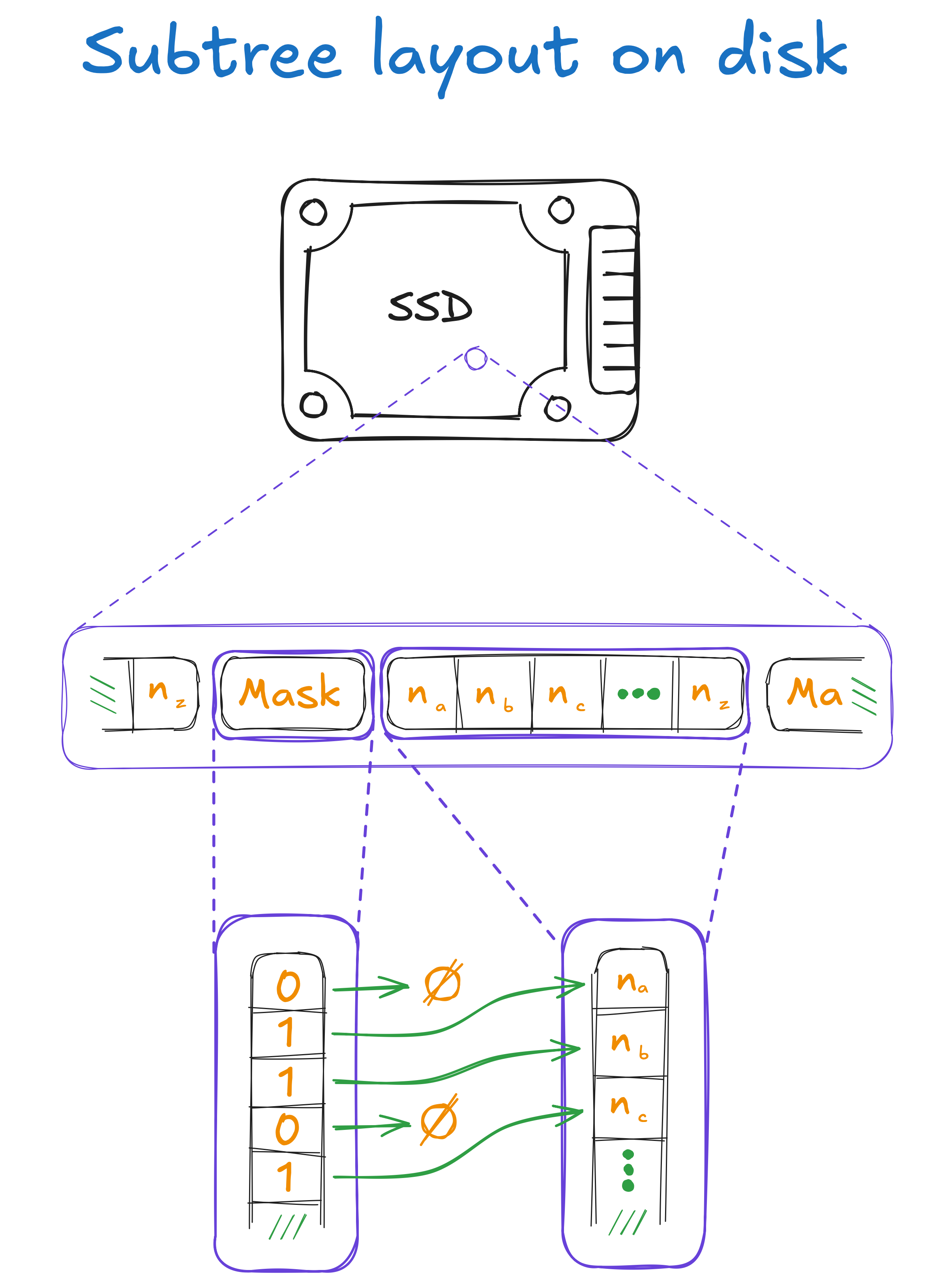
Persistent Subtrees: Every level of the tree below the in-RAM levels is persisted to disk as part of a subtree that contains the nodes for a fixed number of tree levels beneath a common ancestor. Each subtree consists of a bitmask, describing which nodes are present and which are sparse, and the contiguous array of node hashes, containing the values of the nodes. This is laid out as a contiguous block on disk, ensuring read and write locality, and each subtree also acts as self-contained unit of work for operating on the tree in parallel. Subtrees as deployed contain 8 levels, reducing I/O load by a factor of eight and ensuring that the 10K TPS goal was achievable.
The layout of the subtrees on disk. It shows an SSD which it “zooms in on” to show a contiguous region of memory containing a sequence of mask-data pairs. It “zooms in” on one mask and the corresponding data to show the individual bits in the mask and the cells in the data, and uses arrows to mark a correspondence between the set bits and the cells in the data.
Safe Persistence: Persisting the tree is handled through the use of a key-value database, which protects against data corruption by applying modifications atomically in batches. The system is designed to be storage agnostic, though uses RocksDB in production, and ensures that a node can start up in a reasonable time.
Various components of LargeSMT. The in-memory levels are at the top, with the on-disk subtrees below that, and the compact leaf nodes on disk below that. It describes a path to node k1,1 as A, ..., B, ..., C, ...., D, ... to the leaf node E.
The persistence layer of LargeSMT not only enables efficient disk access, but also drastically reduces the startup time for a node. It stores the following information:
Leaves: A mapping from leaf index to value, where the leaf index is given by the 64-bit key prefix and the value contains the sorted key-value pairs inline to enable efficient queries.
Subtrees: A set of mappings from the index at which the subtree attaches to its parent to the data representing the persistent subtree.
Boot Data: A mapping from the node index at layer 23 of the tree to the value of that node. This enables a rapid startup—making building the in-memory tree very efficient—by replacing the need to seek to various subtrees on disk with a single linear read. This also avoids the need to deal with potentially sparse children, further simplifying boot.
LargeSMT also stores some additional metadata, including the value of the root and various counters. This metadata is compact and exists to aid in consistency checking and performance.
This design can technically handle keeping any number of layers in the actual SMT portion. Miden’s choice of 64 strikes a practical balance. It is deep enough to reduce the feasibility of adversarial grinding, while shallow enough to sufficiently bound the path length for query efficiency.
This design borrows heavily from the Sparse Merkle Tree write-up by Pierre-Alain Ouvrard, but tailors the node-batching notion for a fixed depth.
Startup
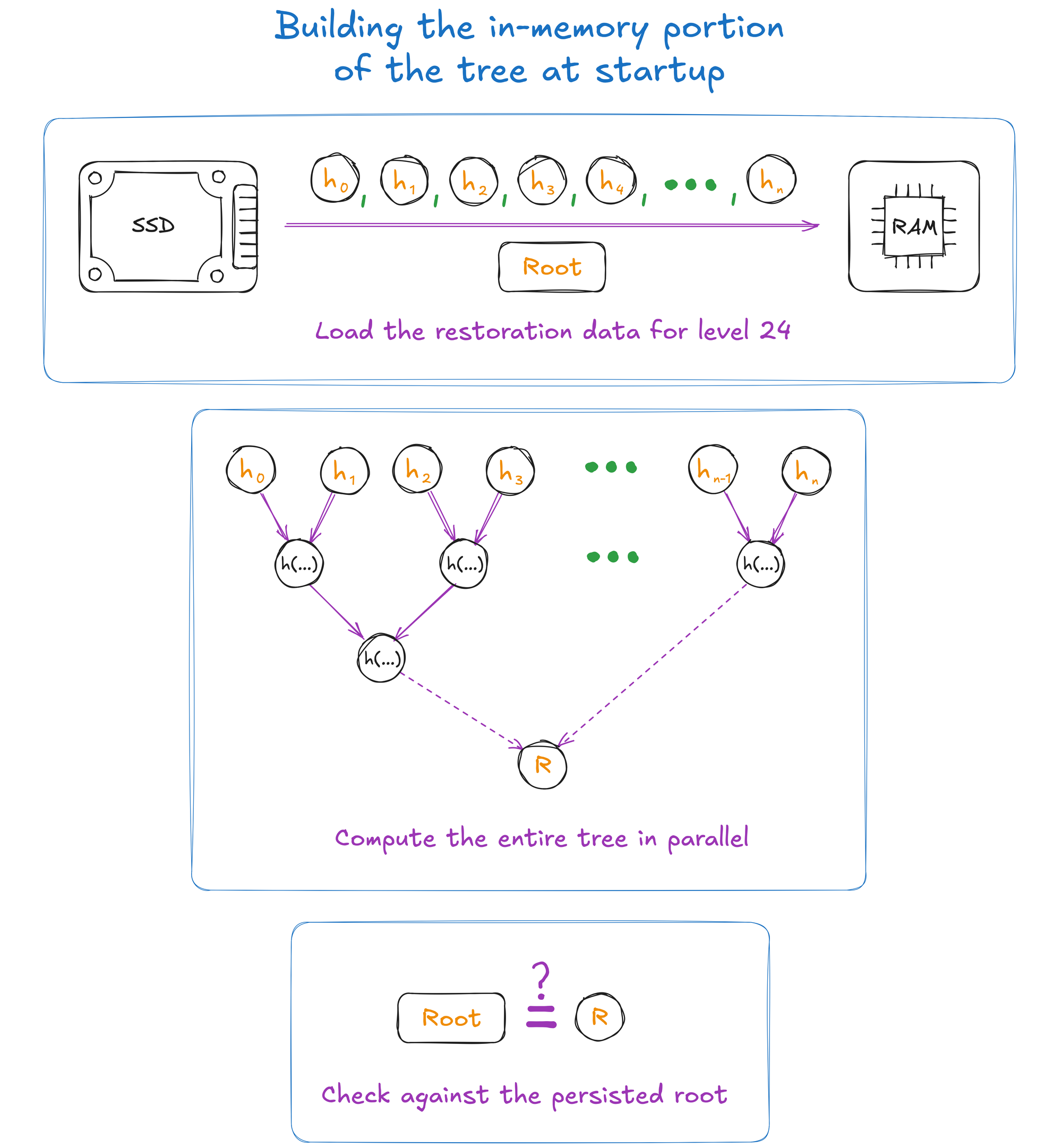
The eagle-eyed reader will note that at no point does LargeSMT ever persist the in-memory portion of the tree. Storing the boot data alone ensures not only predictable cold-start latency, but a startup time that is significantly reduced over a rebuild of the entire depth-64 tree.
By storing the necessary hashes to compute the values of nodes for the bottom of the in-memory tree, LargeSMT computes many orders of magnitude fewer hashes at startup. Around \(2^{24}\) hashes are computed, where a rebuild of the full tree would require at least \(2^{64}\).
The boot process is made even more efficient by keeping the boot data on disk in a contiguous block that can be read in a single pass. The node hashes are then computed in parallel to materialize the tree in memory before checking the computed root against the stored root.
The three stages of building the in-memory tree at startup. At the top is loading the hashes and root from an SSD into RAM, next is the building of the tree from the bottom up in parallel, and at the bottom is the check of the computed root against the loaded root.
This startup process ensures that the work to bring up a node is bounded but also avoids the need to update a R/W-heavy portion of the tree on disk as it is never persisted. We estimate that persisting this portion of the tree would have increased I/O load by 50%, and made it impossible to achieve 10K TPS. LargeSMT also takes advantage of CPU-level parallelism to compute independent portions of the reduction.
Building for Batching and Parallelism
Miden’s workload for their SMTs is batched, performing many queries in one go. LargeSMT was designed to take advantage of this pattern such that a given batch size should run more quickly if more cores are available.
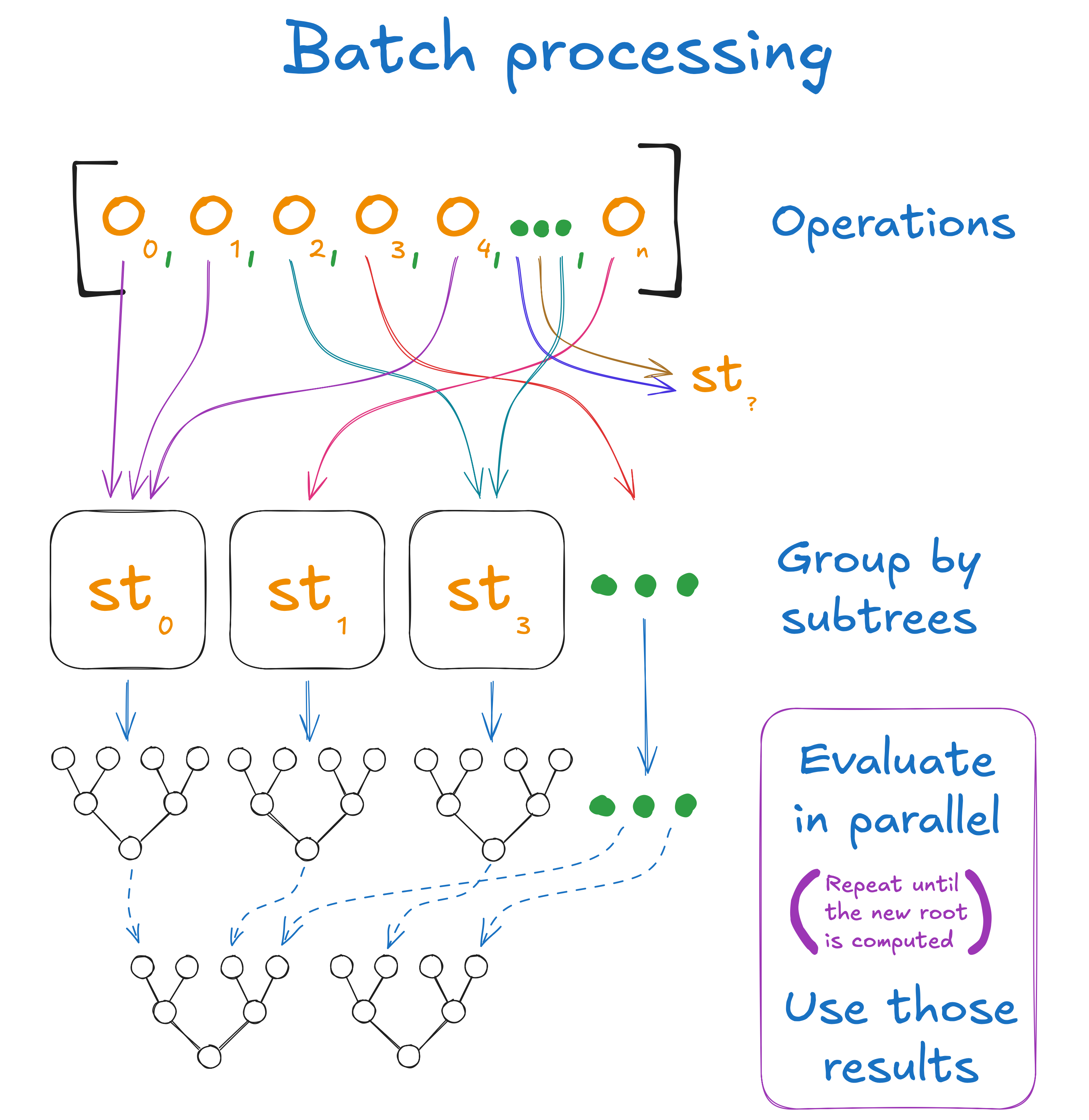
Given a batch of operations (proof generation, insert, and update) to perform on the tree, LargeSMT exploits the batch to gain a wall-clock time reduction as follows. At every level:
The work to do is partitioned into chunks based on which of the subtrees it falls into.
Each chunk has its operations processed in parallel to yield a result.
This result is handed onto the next level, and the process repeats until the in-memory root of the tree is reached.
This structure ensures that each parallel job only has to fetch its own subtree from disk, and can continue as soon as the data arrives. By avoiding a stop-the-world global preload, LargeSMT is able to hide I/O latency by ensuring that the CPU is always doing work.
The batch processing process. It shows a set of operations being partitioned based on the lower-most subtree that they involve. These operations are processed in parallel, using the evaluation results as needed until the new root is computed.
Tasks wait only on the results that they need, and the lack of locks ensures that there are no inter-job dependencies for a given level. This makes it possible to saturate the CPU, and ensures that wall-clock time scales with core count, rather than I/O round-trip time. Exploiting this potential for parallelism has proved crucial to achieving 10K TPS, by doing as much work as possible to shadow the latency of the I/O that would otherwise balloon the execution time.
To ensure crash-resilience without sacrificing throughput, LargeSMT stages data on-demand after each job completes. The commit of the changes is then a single-pass write to disk once the computation of the batch has completed.
Numbers
It’s finally time to back up the claims about LargeSMT’s performance with some numbers! This set of benchmarks looks at batches of 10K operations on tree with \(2^{30}\) (just over a billion) leaves.
CPU
Cold-start existing SMT
10K Insert (total)
10K Update (total)
Proof time
4 cores
~27 s
~1.69–1.93 s
~1.54–1.92 s
~49–83 µs
8 cores
~15–16 s
~1.28–1.31 s
~1.20–1.28 s
~28–79 µs
16 cores
~11–12 s
~0.63–0.99 s
~0.44–0.79 s
~20–28 µs
It exhibits excellent scaling behavior with the number of available cores. With a highly-parallel machine, the amortized per-operation cost for both inserts and updates is in the mid-to-high tens of microseconds, while proofs take less than 30 microseconds in total. However, LargeSMT’s wall-clock execution time is around 2-3x slower in practice than the prior in-memory tree.
Despite this, the tree still achieves a batch execution time low enough—even on the most taxing workloads—to ensure that LargeSMT can achieve the throughput goal of 10K TPS while ensuring that memory usage is bounded to reasonable levels no matter how large the tree gets.
Similarly, the built-in continuous persistence layer brings the cold-start time into the low tens of seconds. With the prior tree, it was not unheard of for node startups to take 20 minutes or more, so this represents a significant reduction in the time taken to spin up a new node.
Disk usage obviously scales with the number of populated leaves—using ~18 GiB for 10 million leaves, ~160 GiB for 100 million leaves, and ~1.4 TiB for 1 billion leaves—the compact leaf representation ensures that this persisted data is far smaller than it would be otherwise.
If you are interested in seeing additional benchmarking results, please check out this PR!
Looking to the Future
While the integration of LargeSMT is not a sufficient condition for Miden to reach the goal of 10K TPS, it is nevertheless a necessary condition. These massive SMTs store crucial data for the network, and without LargeSMT it would never have been possible to reach that goal while also supporting the target residency.
Despite this vast improvement, LargeSMT is far from finished! There is the potential to not only explore alternative storage backends, but also to better tune the system’s configuration. Alterations to the number of in-memory layers will trade off between query performance and startup time, while the sizes of the on-disk subtrees could be tuned to better match real-world query patterns. Similarly, disk usage could also be improved by not storing trivial subtrees and recomputing them on the fly.
LargeSMT’s core premise is simple: support massive trees with quick startup, low memory residency, and query performance suitable for achieving 10K transactions per second. The results are a great success, with the design scaling to billions of keys while staying predictable: you get bounded memory, sub-second batch updates, and microsecond-scale proofs.
If you are reading this blog post and are interested in bringing Reilabs’ expertise in high-performance computing and cryptography to your own project, feel free to reach out to us at hi@reilabs.io!
Hope you have enjoyed this post. If you'd like to stay up to date and receive emails when new content is published, subscribe here!
Keccak, the hash function at the core of Ethereum, is computationally expensive to prove in SNARK circuits, creating a bottleneck for the ZK ecosystem. Our approach combines a GKR-inspired protocol with Groth16, bringing down the average cost of a Keccak instance to <4k R1CS constraints.
Dencun upgrade went live promising up to 10x cost savings to L2 operators. In the lead up to the upgrade, the Ethereum community performed the largest trusted setup ceremony to date, with over 140k participants. Reilabs contributed the backend and parts of cryptography code to this ceremony.
Reilabs introduces Cairo Hints, an extension to Cairo language that makes STARK programs easier to implement and cheaper to execute. Hints enable developers to supplement their programs with data that is difficult to obtain in ZK circuits, allowing them to solve new classes of problems with Cairo.
The EVM’s ability to run computations on-chain has a major weakness: the cost of running code is often too great. Given a lot of the use-cases for this kind of public computation involve more interesting operations, we’ve seen a rapid rise in the use of systems that aim to alleviate those costs.
One of the most foundational concepts on the blockchain is immutability. While this is one of its greatest strengths, it is also a weakness—being able to fix bugs is crucial to building reliable software, but being able to do this is a challenge on chain.
Running any operation on Ethereum network requires careful cost management. For years Polygon has made on-chain applications cheaper and more scalable. Now, they are taking scalability to the next level with the Polygon Miden project, and Reilabs is assisting in making it even more cost-effective.