Running any operation on Ethereum network requires careful cost management. For years Polygon has made on-chain applications cheaper and more scalable. Now, they are taking scalability to the next level with the Polygon Miden project, and Reilabs is assisting in making it even more cost-effective.
Benefits of a ZK rollup
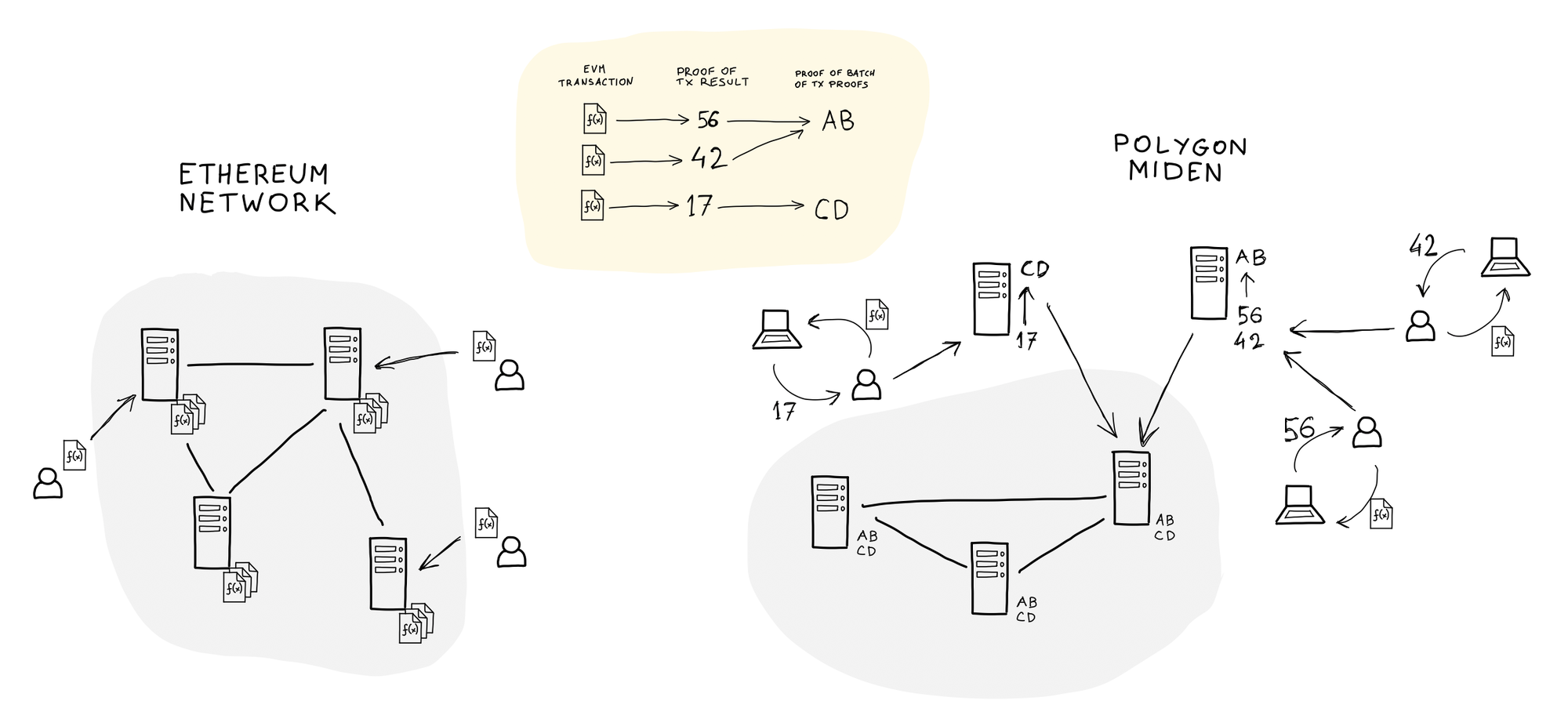
Polygon Miden is, in their own words, a ZK-optimized rollup that utilizes client-side proving. It enables clients to offload resource-intensive calculations from the blockchain, and instead submit results along with a succinct ZK proof showing that those results were obtained correctly.
For example, imagine you enter 1000 identities to a Merkle Tree and need to obtain the new tree root. With ZK proofs, the smart contract doesn’t need to calculate all the intermediate hashes. Instead, it can simply accept the new root value from the client, as long as the attached proof verifies (which is a much smaller and faster operation).
Even better, transaction proofs can be batched into batch proofs, further minimizing costs. A single proof verification can accept results from multiple transactions.
Instead of having each network node process the full contents of each transaction (Ethereum), Miden network nodes only verify small transaction proofs—or even proofs of batches of proofs—significantly reducing the number of on-chain calculations performed by all nodes.
However, generating ZK proofs is computationally intensive. Instead of executing programs directly on an expensive EVM, we now need to perform millions of arithmetic operations off-chain to generate the final succinct proof. To ensure cost savings, we must use efficient algorithms on affordable and powerful hardware. This is where Amazon's AWS Graviton3 processor comes into play.
Benefits of AWS Graviton3
With AWS Graviton, Amazon designs custom processors tailored to deliver the optimal price-performance ratio for cloud workflows. According to Amazon, AWS Graviton offers a 40% improvement in price-performance when compared to traditional x86 processors [1]. ARM, the chip designer, also demonstrated a 30% improvement in price-performance when sequencing a human genome using AWS Graviton3 [2].
Using efficient algorithms
The second ingredient to doing this performantly is an efficient algorithm. Polygon Miden chose the Rescue-Prime Optimized hash (RPO) as the building block of their ZK proof system. RPO is an algebraic hash function that is ZK friendly. It is also recursion-friendly, allowing them to aggregate proofs into batches. RPO works by applying multiple rounds of the following scheme on an array of 12 64-bit numbers:
apply a diffusion matrix,
add constants,
raise to the power of 7,
apply diffusion matrix,
add constants,
raise to the power of 10540996611094048183.
To add to the complexity, these operations are carried out modulo p = 2^64 - 2^32 + 1, also known as a goldilocks prime. After each multiplication, the result must be reduced modulo p, meaning it is divided by p and only the remainder is stored. This explains why these ZK proofs require significant computational effort, as a large number of arithmetic operations are needed to calculate these hashes.
As with everything in the ZK world, this multiplication routine is already heavily optimized through using tricks like Montgomery reduction and clever algorithmic approaches to avoid slow division. A single a * b (mod p) looks like this in Rust (with explicit type ascriptions for clarity):
fn montgomery_multiplication(a: u64, b: u64) -> u64 {
let x: u128 = (a as u128) * (b as u128);
let (low, high): (u64, u64) = (x as u64, (x >> 64) as u64);
let (a, carry): (u64, bool) = low.overflowing_add(low << 32);
let b: u64 = a.wrapping_sub(a >> 32).wrapping_sub(carry as u64);
let (r, borrow): (u64, bool) = high.overflowing_sub(b);
let result: u64 = r.wrapping_sub(0u32.wrapping_sub(borrow as u32) as u64);
result
}
This compiles down to the following (annotated) assembly code:
mul low, a, b ; low = a * b (low 64 bits)
umulh high, a, b ; high = a * b (high 64 bits)
adds a, low, low, lsl #32 ; carry stored in CPU flags!
sub b, a, a, lsr #32
sub b, b, carry ; b = a - (a >> 32) - carry
subs r, high, b ; r = high - b, borrow stored in CPU flags!
mov c, #-4294967295 ; -1 as u32 number in 64-bit register
csel borrow, c, xzr, lo ; set borrow to -1: u32 based on the CPU flag
add result, r, borrow ; result = r + borrow (borrow is negative)
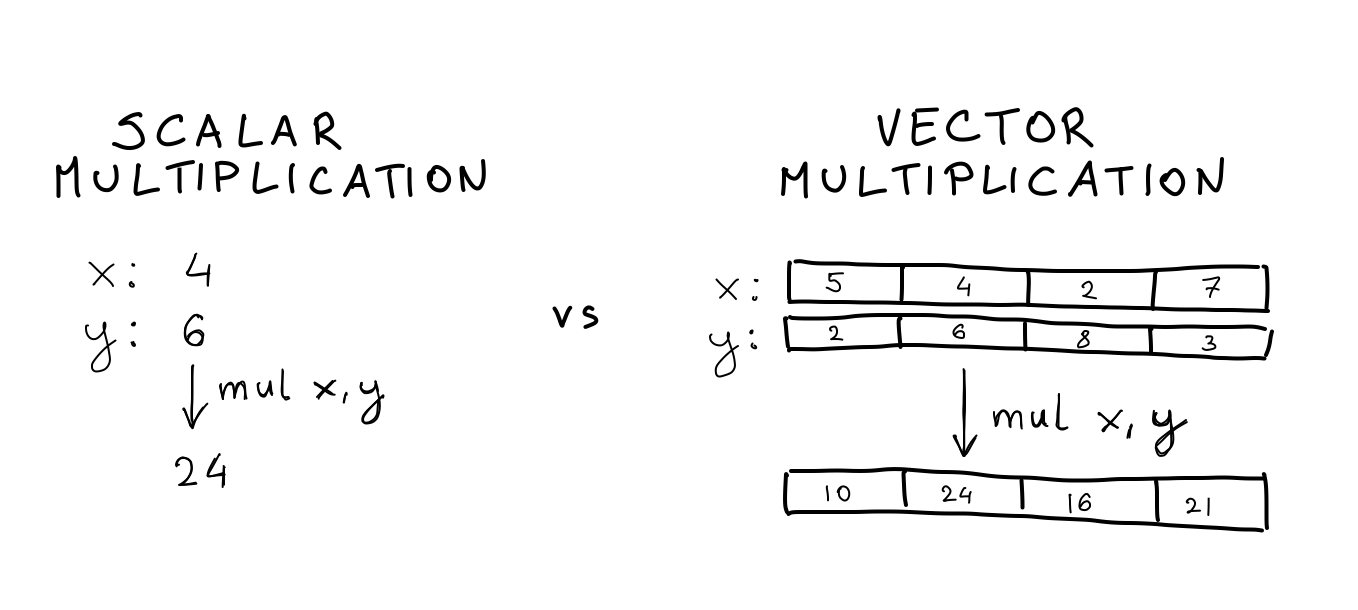
The Graviton3 processors are based on the ARM Neoverse V1 architecture, which introduces Scalable Vector Extension (SVE) instructions. These instructions allow for the simultaneous processing of multiple numbers with a single operation. This is an example of Single-Instruction, Multiple-Data (SIMD).
While SIMD instructions are not new, SVE brings added flexibility to their execution and expands the register size compared to previous ARM implementations. With larger registers, we can process more numbers simultaneously. Graviton3 can handle four 64-bit numbers in a single instruction.
Single instruction, multiple data. By leveraging SIMD, we can process 4x more numbers at once.
The RPO hash processes data in groups of twelve 64-bit numbers. Let's split them into 3 groups of 4 elements and process each group using these new SVE instructions. This should give us a 4x speedup, right...? Not really! To understand why, we need to dig into how CPUs work.
We can describe performance of each CPU instruction using two numbers:
Latency: The number of CPU cycles before the instruction can start executing after it has collected all its operand values.
Throughput: The number of CPU cycles needed for the instruction to complete once it has started executing.
When all instructions are independent, we can rely on the throughput to tell us about performance, and SIMD performs great. However, if one operation needs to wait for the result of another, we need to consider both the latency and throughput. Unfortunately, SIMD operations have much higher latency compared to their scalar counterparts. A simple strategy of replacing scalar operations with vector operations, despite processing 4 things in parallel, gives us 40% worse performance. If our vectors had only 1 element, that’s 560% worse performance per element!
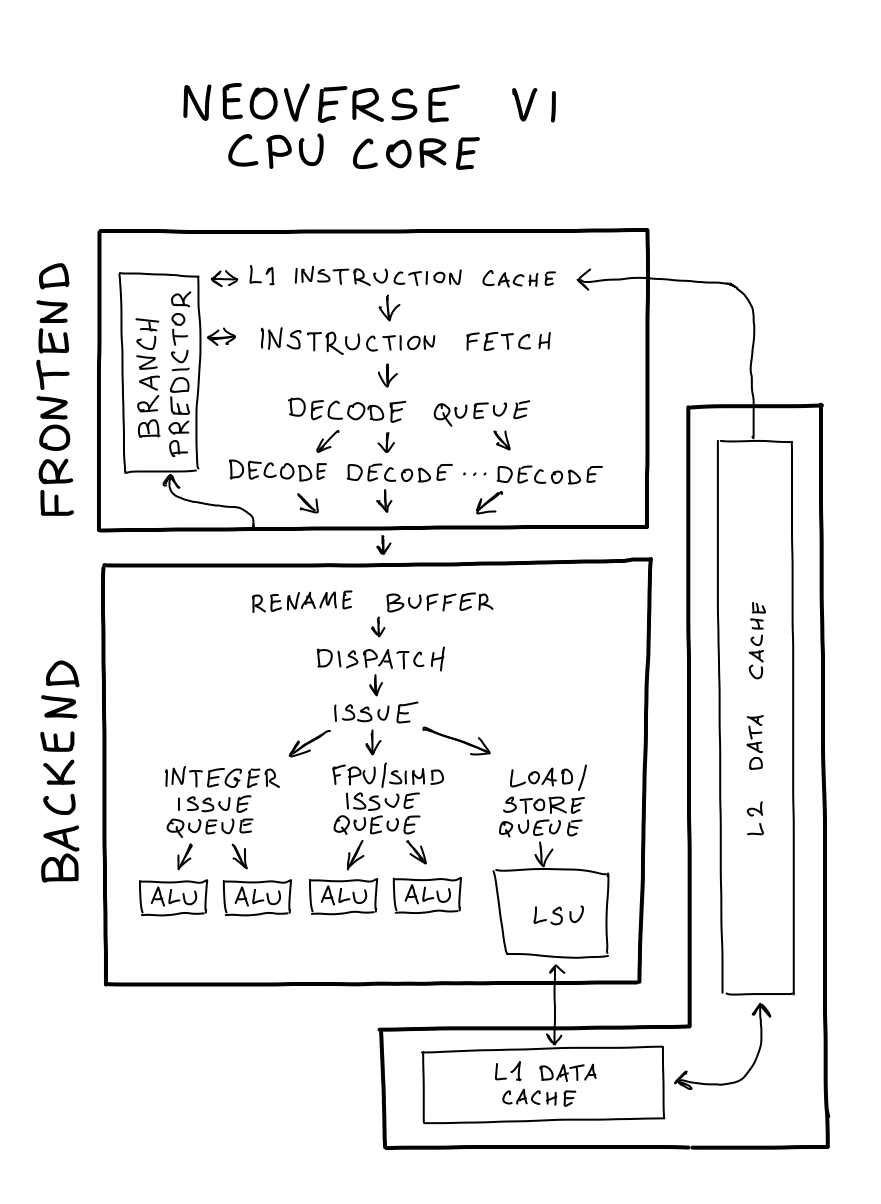
A single CPU operation needs to go through multiple stages of the CPU pipeline before it arrives at one of the computation units. Neoverse V1 has 2 integer (scalar) arithmetic logic units (ALU), and 2 vector (SIMD) arithmetic units per core.
Arriving at the solution
Let's examine the diagram of a single ARM Neoverse V1 core, which serves as the foundation for AWS Graviton3. This core consists of 2 scalar and 2 vector arithmetic logic units (ALU). To make the most of these units, we'll implement two strategies:
Multiplication unrolling: Currently, the Montgomery multiplication is significantly slowed down because most of its 10 steps depend on previous results. We, however, have 3 independent vectors. By interleaving multiplication operations of these vectors, one vector can wait for results while the other two are progressing via pipelining in the CPU. With this change alone, we managed to reduce the execution time from +40% to -30%!
Scalar and vector interleaving: We still have two unused scalar arithmetic units and noticeable latency gaps between vector operations. We can leverage our efficient scalar implementation to fill in these latency gaps. By performing vector operations on only 8 elements of the array (equivalent to 2 vectors) and interleaving them with 4 scalar multiplications, we were able to save an additional 10% of the execution time.
We talked about latency gaps. But how do we know they exist, and how do we know we are addressing them properly? Modern processors, including Graviton3, have hardware performance counters that collect stats about execution: number of instructions started, completed, number of pipeline stalls (when one of the pipeline stages cannot proceed without waiting on another stage), number of cycles, branch mis-predictions etc.
By combining these numbers, we can see how many instructions per cycle are being processed. If the number is lower than 4 (the number of arithmetic units), we most likely have latency gaps. The Linux perf subsystem allows us to tap into these hardware metrics and confirm our hypothesis.
Summary
We have started with an already highly-optimized routine. By combining it with the features of a modern processor we were able to achieve an additional 37% improvement. When you add in the cost savings from the AWS Graviton3 processors, switching from x86 to ARM becomes a significant step in reducing cloud costs.
Writing hand-rolled assembly is a blend of art and science. It can be challenging to precisely measure what the processor is doing. Having knowledge of techniques like unrolling and understanding processor design allowed us to achieve significant gains with relatively small effort.
If your company is interested in reducing compute costs, whether through utilizing SIMD or designing better algorithms, please reach out to Reilabs. We would be happy to help!
Hope you have enjoyed this post. If you'd like to stay up to date and receive emails when new content is published, subscribe here!
Sunspot brings the ease-of-use of Noir to Solana, with developers now able to write, compile, and verify any Noir program on Solana without breaking the bank! In doing so, it unlocks on-chain KYC, private DeFi, secure data availability and more.
Merkle Trees are valued in the blockchain space for their ability to commit to huge amounts of data with a concise value. As a result, they form the cornerstone of many protocols, making the performance of their implementations absolutely crucial for protocol responsiveness.
Keccak, the hash function at the core of Ethereum, is computationally expensive to prove in SNARK circuits, creating a bottleneck for the ZK ecosystem. Our approach combines a GKR-inspired protocol with Groth16, bringing down the average cost of a Keccak instance to <4k R1CS constraints.
Dencun upgrade went live promising up to 10x cost savings to L2 operators. In the lead up to the upgrade, the Ethereum community performed the largest trusted setup ceremony to date, with over 140k participants. Reilabs contributed the backend and parts of cryptography code to this ceremony.
Reilabs introduces Cairo Hints, an extension to Cairo language that makes STARK programs easier to implement and cheaper to execute. Hints enable developers to supplement their programs with data that is difficult to obtain in ZK circuits, allowing them to solve new classes of problems with Cairo.
The EVM’s ability to run computations on-chain has a major weakness: the cost of running code is often too great. Given a lot of the use-cases for this kind of public computation involve more interesting operations, we’ve seen a rapid rise in the use of systems that aim to alleviate those costs.
One of the most foundational concepts on the blockchain is immutability. While this is one of its greatest strengths, it is also a weakness—being able to fix bugs is crucial to building reliable software, but being able to do this is a challenge on chain.